
Introducing IntellAgent: Your Agent Evaluation Framework
Uncover Your Agent's Blind Spots to Unlock Its Full Potential




We’re excited to introduce IntellAgent, an open-source framework that’s revolutionizing how conversational AI systems are evaluated and optimized. Gone are the days of manual edge-case discovery and limited analytics. With IntellAgent, developers can unlock the full potential of their agents by automating edge-case discovery and leveraging rich, actionable insights to ensure proven reliability.
Instead of playing it safe by default, IntellAgent empowers you to push boundaries, expanding your agent’s functionality through robust, data-driven validation. By generating thousands of realistic edge cases tailored to your agent’s specific use case, IntellAgent simulates diverse user interactions, from simple queries to complex, multi-turn conversations.
Armed with comprehensive performance analytics, you’ll gain deep insights into your agent’s behavior, helping you close gaps, identify areas for improvement, and validate enhancements across experiments. With seamless integration into your existing conversational agent workflow and compatibility with LangGraph Agents, IntellAgent effortlessly enhances your AI while offering maximum flexibility and modularity.
Explore our GitHub repository to evaluate your conversational agent.

Bridging the Gap Between Conversational Agents’ Promise and Performance
Conversational agents promise to revolutionize customer engagement, yet the reality often falls short. Instead of delivering versatile, seamless experiences that delight users, businesses grapple with critical reliability issues: hallucinations, inconsistent responses, and policy violations. These challenges force organizations to limit their agents to basic operations with minimal tool integration—undermining user trust and tarnishing brand reputation.
The root of these problems lies in insufficient testing. Many companies rely on small, manually curated datasets that fail to uncover the full spectrum of their conversational agents' vulnerabilities. This limited approach leaves significant performance gaps undiscovered, preventing organizations from realizing the transformative potential of their AI systems.
The τ-bench, the most comprehensive publicly available benchmark for conversational agents, evaluates their ability to interact with users, adhere to domain-specific policies, and effectively utilize API tools. It includes simulations in domains such as retail and airline customer service. However, τ-bench is limited by its reliance on manual curation, offering only 50 samples for airlines and 115 for retail, which restricts scalability and diversity. Additionally, its evaluation focuses on coarse-grained, end-to-end metrics, overlooking critical aspects like policy violations and dialogue flow errors, which limits its ability to provide a thorough assessment.
Our approach overcomes these limitations by offering a fully automated framework that generates diverse scenarios and dialogues at scale. This enables robust evaluations across varied domains, from straightforward tasks to complex edge cases, ensuring comprehensive agent assessment under diverse conditions. Unlike existing benchmarks, our method provides fine-grained insights, evaluating agents across all policy and tool combinations to uncover specific strengths and weaknesses. With this approach, businesses can rigorously test their conversational agents, optimize performance, and finally bridge the gap between promise and reality.
IntellAgent Framework Overview
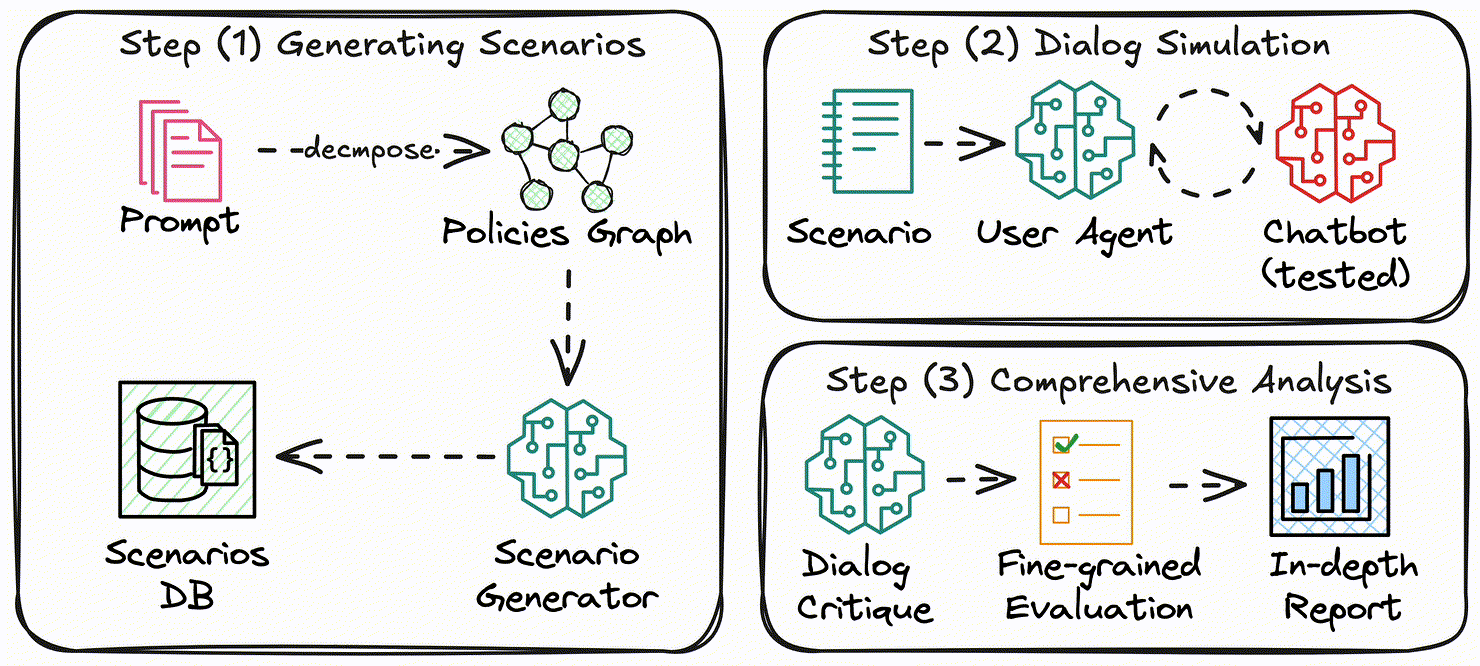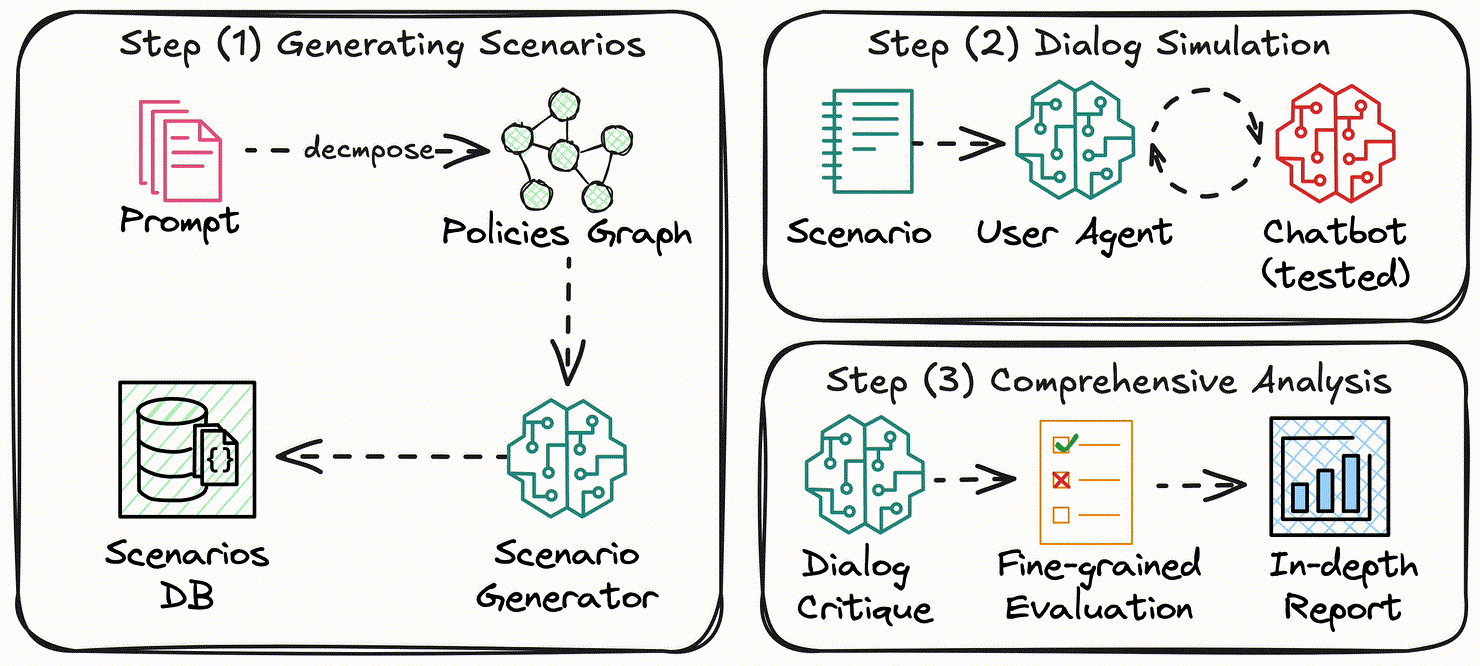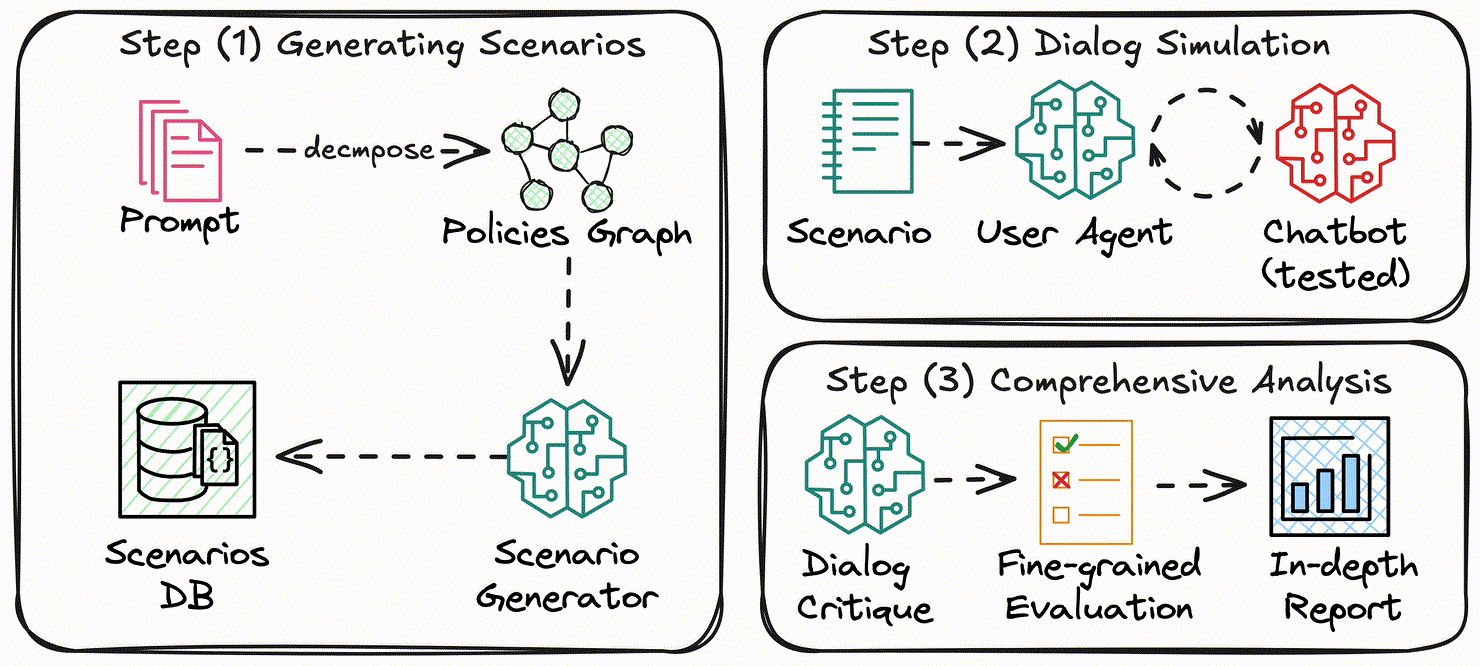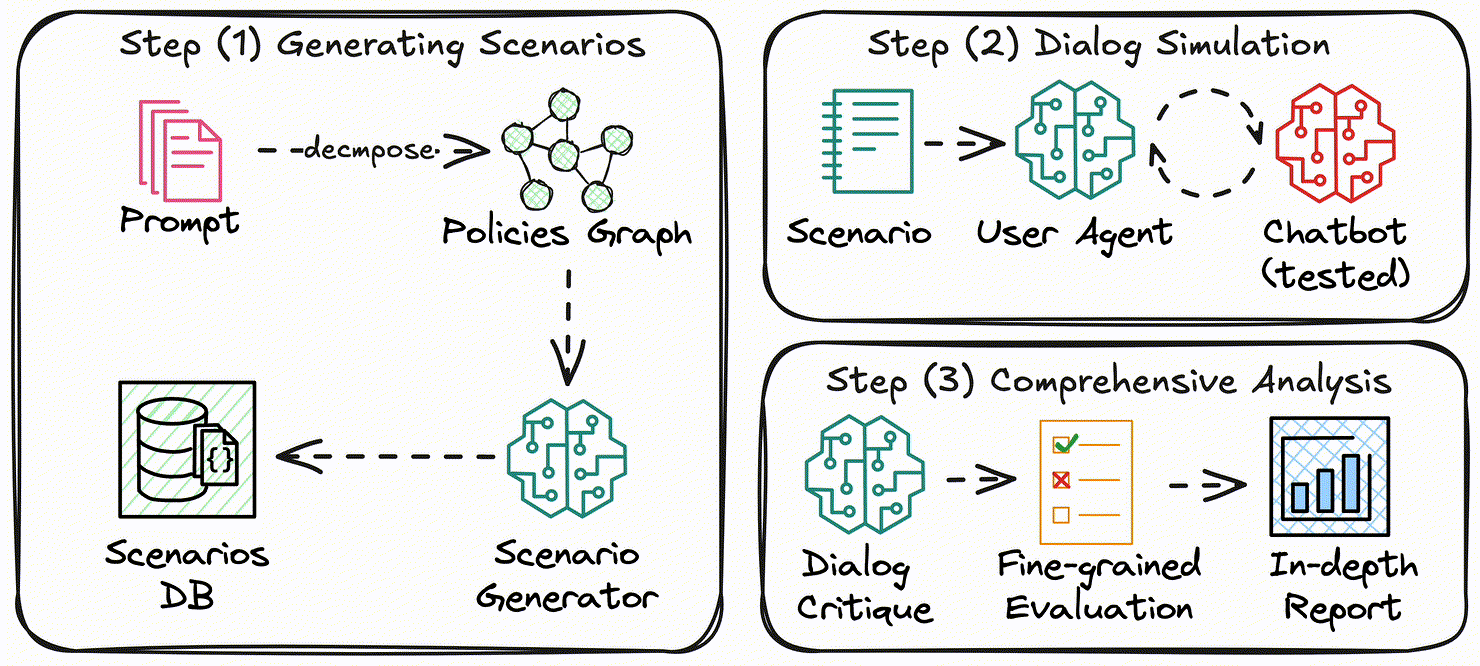
The process begins with Intelligent Scenario Generation, where the agent's configuration—including policies, tools, and database schema—is analyzed to extract key policies and construct a policy graph. This graph serves as the foundation for generating diverse, realistic test scenarios tailored to varying levels of complexity.
In the Dialog Simulation step, a User Agent interacts dynamically with the tested agent in a simulated environment. These interactions replicate real-world conditions, allowing the system to monitor policy compliance and assess the agent's ability to handle diverse challenges.
Finally, the Comprehensive Evaluation phase leverages a Dialog Critic to analyze performance across all interactions. This step validates policy adherence, identifies error patterns, and provides detailed insights into strengths and weaknesses, enabling targeted improvements and enhanced reliability.
For more details on our approach, we encourage you to read the research paper.
Evaluation and Key Findings
We evaluated IntellAgent using several state-of-the-art proprietary large language models (LLMs): GPT-4o, GPT-4o-mini, Gemini-1.5-pro, Gemini-1.5-flash, Claude-3.5-sonnet, and Claude-3.5-haiku. For all models, we utilized their native tool-calling agents, integrated with the tested environment system prompt. During each iteration, the model determined whether to send a message to the user or to call a tool, ensuring a realistic and consistent evaluation environment.
Proven Reliability
IntellAgent demonstrated high reliability by achieving a strong correlation with results from the τ-benchmark, validating the scalability and accuracy of its synthetic approach.
Advanced Policy Analysis
The framework excels in detecting critical policy violations often missed by manual evaluations, such as user consent issues and error recovery failures. It provides granular diagnostics across diverse policy categories, enabling targeted and precise improvements.

Advanced Complexity Analysis
Performance trends revealed a decline as scenario complexity increased, from simple queries to multi-policy interactions. Notably, Gemini-1.5-pro outperformed GPT-4o-mini in low and mid-complexity tasks but aligned at high complexity, illustrating universal challenges in handling demanding scenarios.
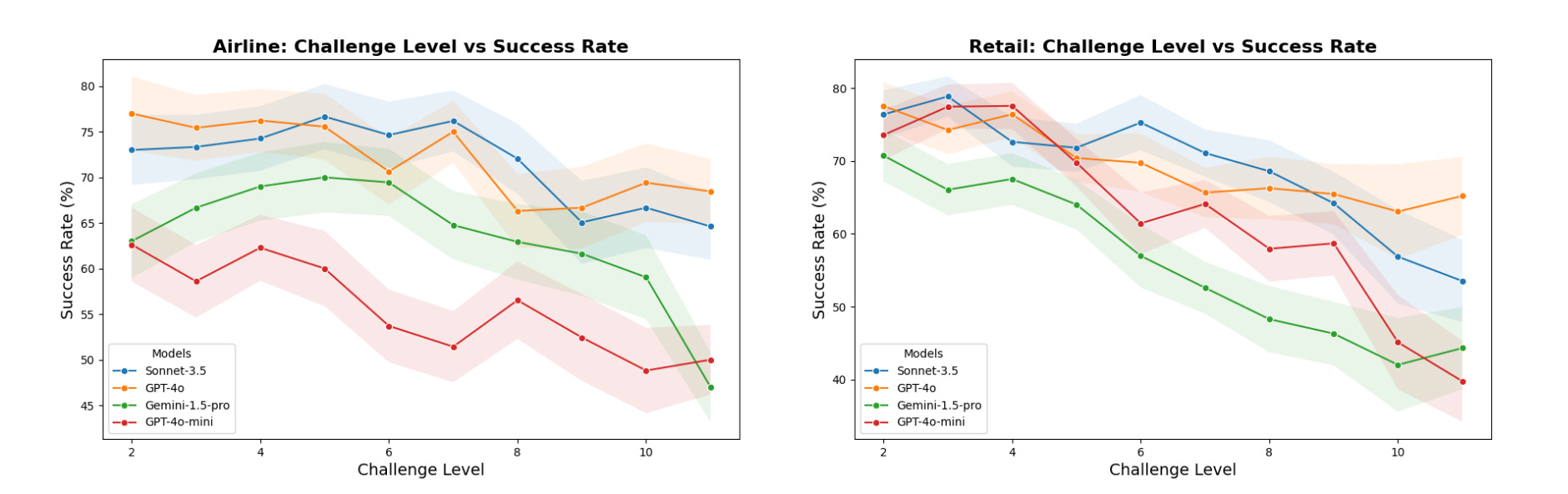
Model Selection Insights
The question we hear time and time again is, “Which model is the best?” The answer: it depends. IntellAgent’s evaluations show that no single model consistently excels across all policy categories or complexity levels. For example, Gemini-1.5-pro outperforms GPT-4o-mini in low and mid-complexity tasks, demonstrating superior handling of structured interactions. However, at higher complexity levels, the performance of both models converges, highlighting universal challenges in addressing demanding scenarios.
This nuanced comparison underscores the importance of aligning model selection with specific use cases. IntellAgent empowers teams with fine-grained diagnostics, providing clear insights into each model’s strengths and weaknesses, enabling data-driven decisions to choose the ideal model for their unique requirements.Join Us in
Building Reliable Conversational AI
We're committed to advancing reliable conversational AI through open collaboration. IntellAgent is now open-source and available on GitHub for testing and evaluation. Join our Discord community to engage in discussions, explore our research paper for technical insights, and contribute to shaping the future of Reliable Conversational AI.
Best,
Ilan and Elad